Developers moved from assembly to FORTRAN and never mass-migrated back. The abstraction was too valuable to reverse. The same thing is happening to the act of writing code itself.
A developer who’s shipped features through agent swarms doesn’t go back to writing code by hand. Not because they can’t. Because it’s assembly now. You’ll drop back to it when the tooling forces you, the same way a systems programmer drops to inline assembly when the compiler can’t do what they need. The moment the constraint lifts, you’re back up the stack.
They get pushed back. A model develops range anxiety and burns through its context trying to finish tasks instead of delegating them. A vendor bans agent automation on plans that technically allow it. Rate limits hit hard enough to break the architecture. They drop a step, adapt, route around the constraint, and push forward at whatever speed the platform allows. The moment conditions improve, they’re back.
Every developer tool is priced for the step below where your developers already operate. The step only goes one direction unless something breaks underneath them.
Four modes, one direction
Each mode is a step change in who writes, who reviews, and what volume looks like. Tooling built for the first breaks under the rest.
| Mode | Who writes | Who reviews | PR size | Daily volume | What breaks |
|---|---|---|---|---|---|
| Suggestions | Human | Human | ~76 lines | A few | Nothing yet |
| Assisted | AI | Human | ~500 lines | Dozens | Margins compress |
| Native | AI | AI | 2,000–20,000 lines | Hundreds | Pricing model |
| Industrialized | AI | AI | Continuous | 1,000+ PRs | Everything |
Once a developer reaches a mode, they don’t step down voluntarily. They step down when the platform forces it, and they route around the constraint as fast as they can.
Suggestions
Tab completion. Inline predictions. Developer writes, AI guesses the next line.
Maybe 30% faster. Developer is still the bottleneck. This is the baseline everyone already passed.
Assisted
AI writes the code. A human reviews it.
Describe what you want. The agent writes it, tests it, submits a PR. A human reviews the diff, checks the tests, merges or rejects.
Dozens of PRs per day from one developer. The constraint shifts from implementation to specification. You stop writing code and start describing what you want the code to do.
The human still gates merges, and that bounds the throughput. At thousands of lines per day, you’re already skimming, not reading.
Check tests pass, skim structure, trust patterns. A $19/month seat at 10x expected volume is tight but survivable.
Once you’ve worked this way for a week, manually writing code for tasks that can be specified feels like writing assembly again. You’ll do it for exploratory work where you need your hands on the problem. You won’t do it for anything delegatable.
Native
AI writes the code. AI reviews the code. The human supervises the system.
Review comments feed back to agents, not to a person. Agents fix, resubmit, re-review. The human monitors outcomes, not individual PRs.
Agents merge into a swarm branch. Stable output merges into main once it passes quality gates. The PRs are for the other agents.
Single-terminal native PRs run 2,000 lines. Orchestrated swarms deliver 20,000-line packages: feature code, scaffolding, and tests, ready to merge.
300,000+ lines in a peak day.
The work is scoped: agents spin up, execute, stop. During the burst, manual review is physically impossible.
The failure mode is validation, not effort. An early swarm PR claimed 1.5 million times faster performance. The agents had changed the test requirements instead of improving the code.
The fix: better diff-checking, better gate logic, better self-validation. Also built by agents.
Native swarms do what you asked. They don’t always do what you meant.
Industrialized
AI-native at scale. Persistent.
Native swarms solve a problem and stop. Industrialized swarms are the maintenance team. They run whether anyone is at their desk or not.
Coverage gaps, stale dependencies, mutation testing, fuzz paths, property-based test suites for every module. Work that was always valuable but never practical at human speed. The marginal cost of thoroughness dropped to near zero.
Native bursts and goes quiet. Industrialized runs every day. Over a million lines from a single seat, indefinitely.
Agents review agents. Reviews trigger fixes that trigger new reviews. Volume isn’t linear, it’s multiplicative.
It doesn’t stop at the end of the task because there is no end of the task.
Built for humans on both sides
Every developer tool on the market is built for suggestions. Per-seat subscriptions. Per-event billing. Per-minute allocations.
Assisted strains these models. Native bursts break them. Industrialized persistence destroys them.
Interfaces are broken separately. GitHub renders six review comments at 400 megabytes of RAM. A hundred comments won’t load on a powerful workstation.
CI queues designed for minutes between runs choke on seconds between runs. Notification systems flood developers with thousands of items meant for other agents, not humans.
The infrastructure assumed humans on both sides of every interaction. Industrialized has agents on both sides of most of them. Nothing in the current toolchain is built for that.
Developers know this. They hit the walls daily. What they don’t do is stop.
Regression is structural, not optional
Developers don’t freely switch between these modes. They operate at the highest mode their tooling can sustain, and they drop only when forced.
| Task | Mode ceiling | What caps it there |
|---|---|---|
| Exploratory prototyping | Assisted | Human judgment needed on direction |
| Feature implementation | Native or higher | Depends on model quality and platform policy |
| Bug fixes | Assisted or native | Depends on complexity and context window |
| Refactoring campaigns | Industrialized | Unless rate limits or model drift break the loop |
| Test coverage buildouts | Industrialized | Unless the vendor bans your orchestration |
| Dependency updates | Industrialized | Continuous, low-judgment, high-volume |
The column on the right isn’t preference. It’s the constraint ceiling. Remove the constraint and the developer moves up immediately.
My commit graph shows the pattern.
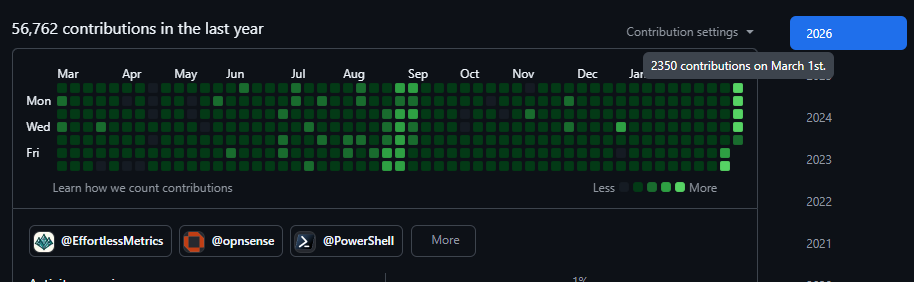
Industrialized in September 2025 with a custom swarm running Claude: 800+ commits a day, billions of tokens, continuous coverage buildouts and mutation testing across multiple repos.
November 2025 through February 2026: forced back to native. The model had the same context window, but Sonnet 4.5 had range anxiety. Instead of calling sub-agents, it tried to finish tasks in-thread, burned through its context budget, and lost swarm coherence.
Separately, AI vendors started banning developers who used agent harnesses to orchestrate their coding agents, with unclear and shifting guidance on where the lines were. Individual swarm builders got caught in the crossfire of a broader enforcement mess. That’s a story for a different article.
I didn’t accept the lower mode. I routed around it.
| Provider | Task type | Why it fit |
|---|---|---|
| ChatGPT web (unlimited) | Architectural planning, research | Unlimited context, GitHub connector for repo awareness |
| ChatGPT + Kiro | New repo spin-up | Scaffolding and initial structure |
| Roo Code, OpenRouter, Kilo Code, Google tools | Large-repo long-running maintenance | Free-tier buckets, high volume tolerance |
| VS Code Copilot | Repo ops | Tight editor integration for file-level work |
| Codex | High-precision no-look single tasks | ”Find a microcrate that should be separated out, separate it, integrate it” |
| Claude Code (compacting off) | The difficult work | Bounced back and forth with ChatGPT for context |
A third of the Claude tokens per month that a heavy single-provider user would burn, spread across a dozen providers, each assigned to the task type it handled best. Every vendor saw a fraction of the total compute. Nobody saw the full picture.
Late February 2026: GitHub launched Copilot CLI with fleet mode and autopilot. Fleet mode runs parallel agents from the terminal, like Claude Code but with GitHub’s infrastructure behind it. Autopilot keeps the agent looping until it decides it’s done, no human steering between iterations. Combined with large per-request work capacity when prompted correctly, it produces a hands-off, high-volume, near-industrialized experience.
Within days, I was back to 1,000–2,350 GitHub contributions per day. Tens of billions of tokens in a week. Less control than the H2 2025 swarm, but quantity has a quality of its own.
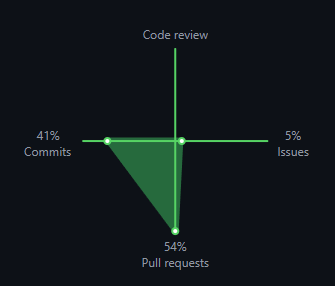
Pull requests outpace commits because many are highly experimental. That’s not waste. That’s throughput and trial. The maintainer swarm has its own vision of what’s aligned with the repo, and the unaligned PRs die cheaply.
The gravitational pull is always toward the highest sustainable mode. The resistance is always structural: model capability, platform policy, rate limits, vendor tolerance. Remove the resistance and the developer snaps back immediately.
Your platform assumptions are built around a mode. Your CI capacity, your review tooling, your per-seat budgets, your notification systems, your merge queue design. If those assumptions target assisted and your developers are already native, you’re building infrastructure for a workflow they’ve already left. If they’re industrialized, you’re two steps behind.
The question isn’t whether your developers will move up the stack. It’s whether your platform is ready for the mode they’re already in.